


今回は、VoicePingの音声入力機能(Speech-to-Text=以下STT)について詳しくご紹介していきます。どのようにシステムを構築し組み込んでいったのか、また、クラウドサービスという形をとりながら、どのようにして最大限の効率性と品質を追求することができたのか見ていきましょう。
快適なリモートワークを実現する機能が満載のVoicePingは、離れて仕事をするリモートチームにとってまさに理想的なツールです。現在VoicePingでは、プレミアムプランを1年間無料で提供しています。お申込みはhttps://voice-ping.com/ から!
記事概要
音声認識からテキスト化まで行うシステム(STT)をゼロから構築し、高い質や精度までもっていく、というのはとても難しいことなのです。だからこそ多くの企業や開発者たちは、自分たちでシステムを構築するよりも、既存のSaaSソリューションを選択するという傾向にあるのです。既存のサービスは、質が高く、さまざまな言語にも対応できてしまうからです。
しかしその場合に課題となるのがコストです。多くのサービスは、「使った分だけ支払う」という料金体系を取っており、使い方によっては安く済むこともあるかもしれませんが、逆に少しでも使い過ぎると高くついてしまいます。「どのように、どれだけ使うか」というのがポイントです。
今回は、STT機能を採用するため、VoicePingが「いかにコストを削減したか」をご紹介します。費用がかかりがちなSTTを、いかに安価に導入するのか。私たちが立てた戦略です。
VoicePingは、会議中「ユーザーの大半は聞き役に徹している」、つまり「発言しない状態にある」という事実に目をつけ、VAD(Voice Activity Detection)ライブラリを使い、この「(ユーザーが声を発しない時間に生じる)無音の音声を拾わない」という戦略を立てるところから開発を進めました。
開発にあたり私たちが直面した課題についても、どのように解決策をとったのかご紹介していきます。
はじめに
「Speech-to-Text(STT)」は、「自動音声認識(ASR=Automatic Speech Recognition)」とも呼ばれ、YouTubeの自動字幕生成、Siri・アレクサ・コルタナなどのバーチャルアシスタント、その他数多くのアプリに活用されていることで知られています。
VoicePingでは、会議中に発言と同時にリアルタイムでテキスト化する「文字起こし機能」として使用されています。同時に言語翻訳も行い、翻訳テキストも表示させることができます。さらにSlackと同期することで、このように文字起こしされた情報をワークスペース上で共有することができ、会議で話し合われた情報を安全に記録することができます。
文字起こしされた議事録とSlackを同期することで、会議中に話し合われた議題を忘れないようピン留めしたり、特定の発言をブックマークするなど、Slack上のさまざまな機能と関連づけて活用することができます。自分に割り振られたタスクをすぐに振り返ったり、もしくは会議時間が足りず話し合いが十分に行われなかった課題についてSlackスレッド上で引き続き議論をしたり、といったことも可能になるのです。
インプリメンテーション
「音声をテキスト変換するAIシステムの構築」というのは決して簡単なことではありません。このように、ブログ記事1本で語ることができるような話題ではありませんし、また、ひとりでこなせるような仕事でもありません。AIに学習させ、その使用可能性を検証し認証するためには、膨大な音声ファイルやテキスト化情報が必要になってきます。さらに他言語サポートも行うシステムの場合、そうした他言語の情報なども必要となるため、仕事は増すばかりです。これについては、私自身「じっくり説明したい」と思うものの、正直どこから説明し始めればいいのか検討もつきません。
幸い、現在では数多くのこうしたサービスを利用することができますし、質も日々向上しています。場合によっては、プロが行うテープ起こしの質に匹敵する精度のものも存在します。しかし問題はコストです。運営するツールのユーザー数や収益にもよりますが、こうしたサービスは一般的に費用が高く、継続利用が難しいという場合も多いでしょう。そこで、解決策を2つご紹介します。
まずひとつめは、無料サービスの利用です。ほとんどのサービスは、利用時間や使用条件に制限があるものの、無料版を提供しています。「無料版ではやはり物足りない」という場合は、有料のSaaSソリューションを使うほかありませんが、実験的に提供されているWeb Speech APIを利用するという手も。Google ChromeやMicrosoft Edgeのように、すでにWeb Speech APIを実装しているブラウザもあります。
しかし、素晴らしいツールではあるものの、やはり「制限が設けられている」ということ、そしてあくまで実験的なAPIであるため、「すべてのブラウザが実装しているわけではない」という点が課題です。ユーザーに、特定のブラウザを使うよう促さなければならなくなってしまうとなると、ツール自体の評価低下につながることも考えられます。
さらに、API自体にも制限が。今のところ、使用する入力デバイスを選択する方法はなく、.start()を呼び出すことで、つねにデフォルトの入力デバイスから音声録音を開始するという方法を取るしかありません。
こうした課題もあり、私たちは、第3者が提供するサービスを利用することに。当然経費がかかるため、コスト削減の方法を模索することになりました。これが私たちが提案するふたつ目の解決策ということになりますが、これについては次の章で詳しく見ていきましょう。
コスト削減
こうしたサービスを利用する場合、費用は作業量に応じ課されるというのが一般的です。STTソリューションの場合、1時間あたり平均1~1.5ドル程度と言われています。使用量が多い場合、月8万時間にも相当することが考えられ、その場合、1時間0.5ドルほどコストがかかります。
こうしたサービスに音声データを送信した場合、実際に音声が含まれているかどうかという点は考慮されません。音が入っていようがいまいがデータ全体が処理されてしまうため、無音の部分についてもデータ処理したものと見なされ、料金が発生してしまうのです。私たちが問題視したのはこの点でした。
このような料金体系下、5人が参加する会議を1時間行うとしましょう。ここでかかる費用は5ドル程度ということになりますね。さらに、このチームが同様のミーティングを月に6回行うものとすると、これだけで月30ドルほどの費用がかかります。参加者が「5人ではなく10人」といった場合は、このチームだけで月60ドル、さらに10チームが同様のミーティングを開催すれば、ひと月だけ600ドルものコストがかかってしまうというわけです。コストがかかっても、それに見合ったサービス利用ができていれば問題ないでしょう。ただ、10人ものメンバーが参加する会議において、こうした「STTサービスを最大限活用する!」というのは正直難しいところです。「10人全員が同時に発言する」などという場面は起こり得ないからです。通常、ひとりだけが発言をした状態で会議は進められるでしょう。
アジャイルチームの「振り返りミーティング(スプリント・レトロスペクティブ)」に参加したことはありますか?これは、時間を区切りながら、メンバー全員がスプリント(スクラムチームが作業を効率よく行うために設定する短い期間)について、良かった点・改善すべき点を書き出すというミーティングスタイルで、参加したことがある人は分かるかと思いますが、ここでは発言をする必要がありません。STTを利用するのであれば、これは大きな無駄です。
こうした無駄をなくすためにはどうしたらよいでしょう。分かりやすいのは、「マイクがミュート時はSTTをオフにする」という方法です。こうすれば大幅に無駄を削減することができますが、「各ユーザーが都度マイクをオフにする」というのはあまり現実的な得策とは言えません。会議の参加者が多くなればなおのこと、全員が確実にマイクを切ったりつけたりするのはほぼ不可能です。誰かしら、話していない状態でもマイクをオンにしたままにしておくでしょう。
「発言もしていないのにマイクをオン状態にしておくことが悪い」ということではありません。発言のたび、マイクをつけたり消したりするのは実際わずらわしいですし、声や音を発しない限り、マイクをオンにした状態にしていても何ら問題はありません。
マイクがオフ状態で話をし始めた場合、オンにするようリマインドしてくれるアラート機能も付いてはいるものの、VoicePingは、「会議中は基本的にマイクをオンにしておいた方がいい」と思っています。ミュート機能は、電話や他の要件などのため、いったん会議とは関係なく発言しなければならない場合に限り使われるものだと思います。
また、VoicePingは優れたノイズリダクションを搭載しているため、会議中ずっとマイクをオンにしていても、雑音などで他者を邪魔する心配がありません。このノイズリダクション機能については別記事をご参照ください。
ただ実際、多くのユーザーが「話をしない状態にありながらマイクをオンにしている」ため、この分のデータについては無駄を省かなくてはなりません。そこで私たちは、音声をサービスに送る(音声データをテキスト化するという作業が行われる)前に、VAD(Voice Active Detection)を使い音声を前処理することを思いつきました。
ここからはコードをご紹介します。まずは初期設定と、それによる結果から見ていきましょう。
初期設定
私たちが使っているのはReactとTypeScript。今回はReactのフックを使用した例を紹介します。私たちはAzure Speech to Textサービスを使用しているため例ではAzure APIが出てきますが、使用量を減らすための方法としては、どんなサービスにも有効です。
カスタムフックuseSpeechToTextを作成しました。後ほどコードを紹介していきますが、ルートコンポーネントの例をお見せします。
このコードは、下記2点を表しています。
- マイクをミュート/ミュート解除するボタン。
- 認識された音声リストを
●部分的/途中結果は赤で表示
●最終結果は黒で表示
コンポーネント上に結果配列を定義し、関数showMessageには、最後のSTT結果、もしくは部分的な結果を要素として置き換えるだけです。下記のビデオも参考にしてみてください。
●クリックしミュートを解除した後、テキストが認識される。
●開発ツール(Dev Tools)のネットワークタブを見ると、ミュートになっていない状態ではデータが送信されていることが分かる。
上記コードを見ればわかるように、STTサービスを呼び出すための法則はありません。法則はすべててuseSpeechToTextフック内にあり、下記のコードから確認することができます。
細かい点は多数ありますが、ここで最も重要なのはデータをサービスに送信する場所です。送信は、関数onAudioProcess内、具体的にはpushStream.write(block.bytes);の呼び出し(73行目)で行われています。使用量を減らすための大きな変更点は、このあたりになります。
このビデオで分かるとおり、マイクがミュートにされていない場合、続けてサービスにデータ送信しています。これを修正するために、このフックにVADを統合します。
ボイス・アクティブ・ディテクション(VAD=音声区間検出)
音声を認識し文字起こしするのは容易なことではありません。自分たちの力で、ゼロからこうした機能を取り込むというのは実際とても複雑です。だからこそサービスに対価を支払う価値があるのですが、かと言って実際、無音の音声にはテキスト化する要素がありません。これを識別するのはさほど複雑ではなく、私たちでもできるのです。しかし、他の人がすでに作り上げてくれた無料ツールがあります。私たちが開発する必要はなく、下記2機能がすでに含まれています。
●https://www.npmjs.com/package/hark
●https://www.npmjs.com/package/voice-activity-detection
私たちは、使いやすいharkを利用しフックを作ることにしました。
このコードでは、すでに埋め込まれているMediaStreamをパラメータとして受け取り、ストリーム上でharkをインスタンス化し、harkのイベント speakingと stopped_speakingの両方に、ユーザーが話しているかどうかを示すブール値を設定する関数をバインドします。これを使い、STTのオン・オフを切り替えます。しかしこれはそれほど簡単な作業ではなく、まずはいくつか課題を解消する必要があります。
VADコードをSTTコードへ統合
useSpeechToTextフックの前バージョンでは、サービスにデータを送信すべきかどうかをチェックするため、このReact RefmutedRefを使った下記コードがありました。
mutedパラメータを直接確認する代わりに、このrefを使用。なぜかというと、関数onAudioProcessは、AzureのインスタンスSpeechRecognizerをインスタンス化するのと同じuseEffectフックの中で定義されているため、Azureインスタンスの再生成を防ぐ必要があるのです。
VADを統合するために、 streamingFlagRefという新しいフラグを使っていきます。これはミュート状態(mutedパラメータ )と、 useAudioActiveフックで定義したVADの状態(ここではspeakerActive変数で使用)に基づいています。また、running.currentを使用し、Azure インスタンスが初期化される前にストリーミングされないようにしています。
これらの変数はすべて、shouldStream変数にANDブール式で保持しており、ここでの変化はrefstreamingFlagRef の値を変えるuseEffectの要因となります。
そして、サービスにデータ送信するため、pushStream.write(block.bytes);を呼び出す際に、if (!mutedRef.current)ではなく、if (streamingFlagRef.current)を確認するように変更します。これらがコードの変更点になります。
下記ビデオで確認できるように、会話を中断するとデータ送信が停止されますが、ここで新たな問題が発生します。
ビデオの通り、ストリーミングがあまりに早く中断されてしまうようなのです。この原因として考えられるのは下記のような点です。
●赤で表示されている部分的な結果にひっかかってしまう。
●間をあけ再び話し始めると、新しい文として認識されるのではなく、間隔を空けることなく前の文にそのまま続き認識されてしまう。
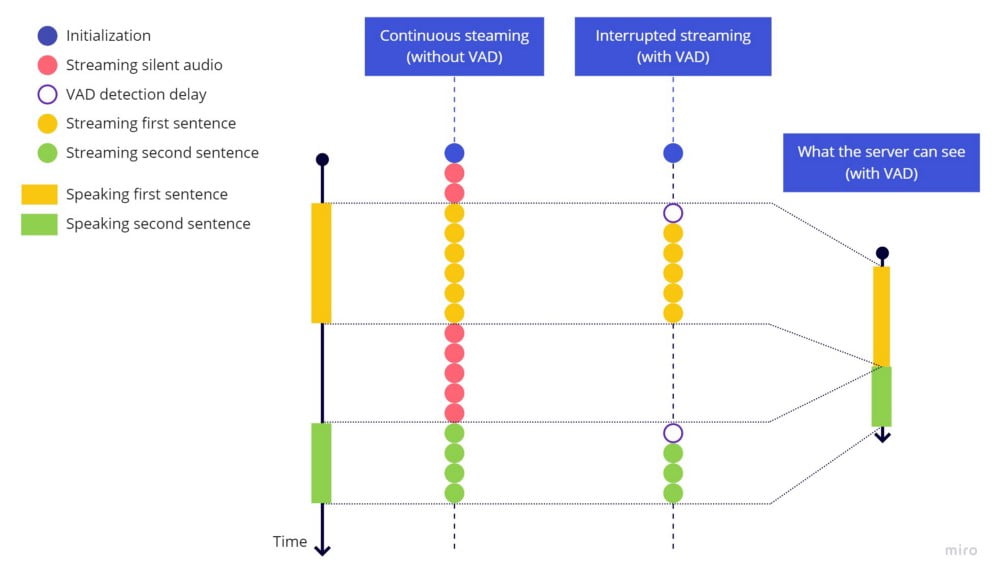
これは、サービスが「文の終わり」と「始まり」を認識するため、一時停止を必要とすることに起因します。少しでも「無音の音声」を流さない限り、サーバーは2文を1文として認識してしまうのです。(図・右の線で表示されている通り。)
この問題を解消するには、ストリーミングを停止する前にタイムアウトする必要があります。下記、ハイライトされた部分を含み試してみましょう。
もう一度試してみると、このような結果になります。
確認できる通り、ストリーミング停止前にタイムアウトを入れることで、各文の終わりと始まりが認識され、異なる2文として識別されました。ただ、早口で話してしまうと、文の始まり部分がカットされてしまうようです。再び話し始めてから、VADライブラリが何らかの音を検出して再びストリーム送信を開始するまでに遅延が生じるためです。
文を始める際、VAD検出動作に遅延があることを念頭に置いておきましょう。
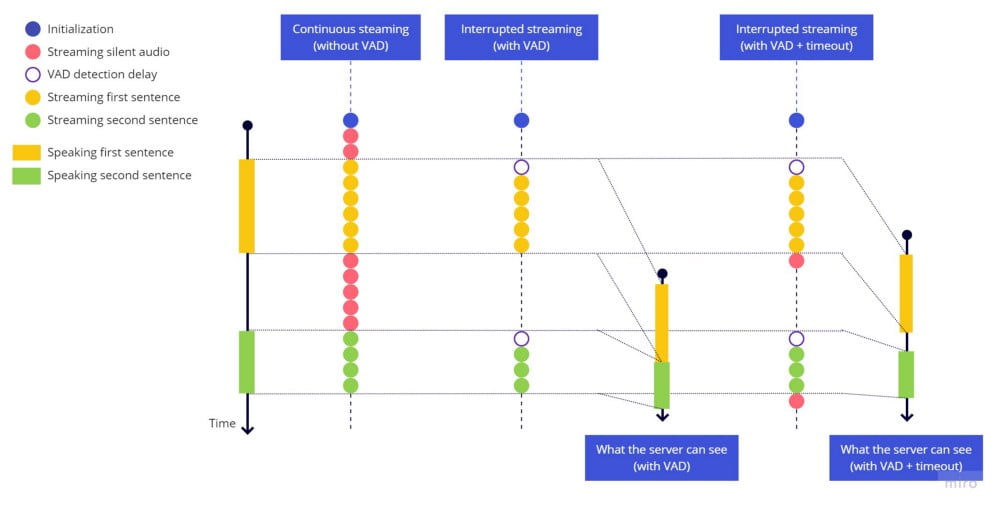
ストリーム送信を開始すると、この遅延のため、最初の単語が漏れた状態になってしまいました。文末でも似たような問題が発生しましたが、ここにはタイムアウトを追加することはできません。タイムアウトはすでに設定されている必要があるため、あとあと追加することができないのです。
VADライブラリがとても敏感に反応するというのも、この問題を悪化させています。どんなに些細な一時停止もhark_stoppedの引き金となってしまい、ある種のバウンシング効果によって、文の中で何度もストリーミングが開始されたり止まったりといった状況が起こってしまうのです。
最終解決策
この課題2点は関わり合っており、「カットオフ」を抜きにバウンシング問題を処理することは難しいため、両方の問題を同時に扱っていきます。
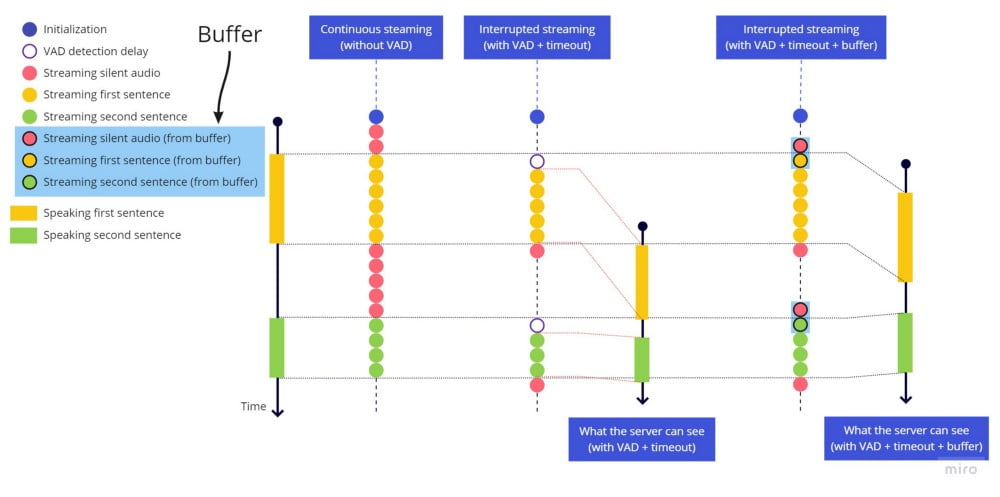
カットオフの問題を解決するためには、発言の頭にタイムアウトを追加したとしても、最後に追加するのと同じでは意味がないため、最後2秒間の音声を保持してくれる「バッファ」を追加する必要があります。そのため、harkが音声を検出すると、ライブストリーミングを送信する直前、まずバッファ全体を送信します。遅延時間はさほど大きくありませんが、言語によっては、音声開始前に空白や無音があった方が精度が高くなる場合が見られたため、2秒としました。
バウンシング効果を修正するため、harkイベントstop_speaking が誘因されるたび、2秒間のタイムアウトを入れ、この2秒が経過した後にのみストリーム送信を停止するようにします。しかし、この間に何らかの音声(speaking hark)が検出された場合は、タイムアウトを中止、停止しなかったかのようにストリーム送信を継続します。
下記、変更箇所です。
- ファイルの頭に定数
BUFFER_SECONDSを追加し、バッファサイズを秒単位に保ちます。 - バッファ配列を保持するため、フック、インプリメンテーション頭にref
bufferBlocksを追加。 - バウンシング効果を処理するタイムアウトを、ref
streamingFlagRefをコントロールするuseEffect内に追加。 - 音声をサービスに送信できているかどうか、
onAudioProcess内を確認。
●可能であればまずバッファを送信し(空ではない場合)、次にライブストリーミングに関わる現ブロックを送信する。
●できない場合は、現ブロックをバッファ配列の最後に追加。もし最大値に達した場合、バッファ最初の要素を削除し、定数BUFFER_SECONDSに定義したものと同じバッファサイズを維持する。 - 最後の
useEffectクリーン関数でバッファ内を整理し、マイクのミュート・ミュート解除に備え、きれいな状態でバッファを開始できるようにしておく。
どのように行うのか見ていきましょう。
音声を検出しライブストリームを開始する前に、いつでも最後の数秒間を送信できるようバッファを利用すると、次のようになります。
最後に
Chrome開発ツールの「ネットワーク」タブでも確認できるように、Azureサービスに送信されるのは、私たちが話している間に限ったデータです。この記事で解決方法をご紹介した課題は、VoicePing開発時に実際私たちが直面したものですが、現在私たちが使用するコードは、ここでご紹介したコードとは多少違う点もあります。そのひとつとして、AudioWorkletNodeの代わりに、createScriptProcessor(非推奨API) を代用しているという点です。これは、Web Workersを使い、アプリのメインイベントループ内でのオーディオ処理を避けるというものですが、今回は分かりやすく説明するため、スクリプトプロフェッサを例にとりました。
もう一点、バウンシング効果処理をフラグ値 streamingFlagRef を定義するコード内に混在させるのではなく、harkの使用をカプセル化した useAudioActive 内に保持するという構造上の問題があります。 私たちのコード上では、 useAudioActiveを複数箇所で使用しており、さらにこうした他の箇所においてはバウンシング効果をそのままにしておきたかったため、ここに変更を加えました。
VoicePing、ぜひ一度お試しください。 https://voice-ping.com/
最終コード
すべての変更点を反映させた最終コードはこちらです。



